mtp综述¶
MTP(Multi-Token Prediction,多Token预测)是DeepSeek中提出的一种用于单次生成多个token的并行解码方法。 MTP并行解码的核心思想是在推理过程中会同时预测多个token,从而显著提升模型生成速度。
原始论文详见:https://arxiv.org/pdf/2404.19737
MTP推理的流程简图如下所示(以MTP=1为例):
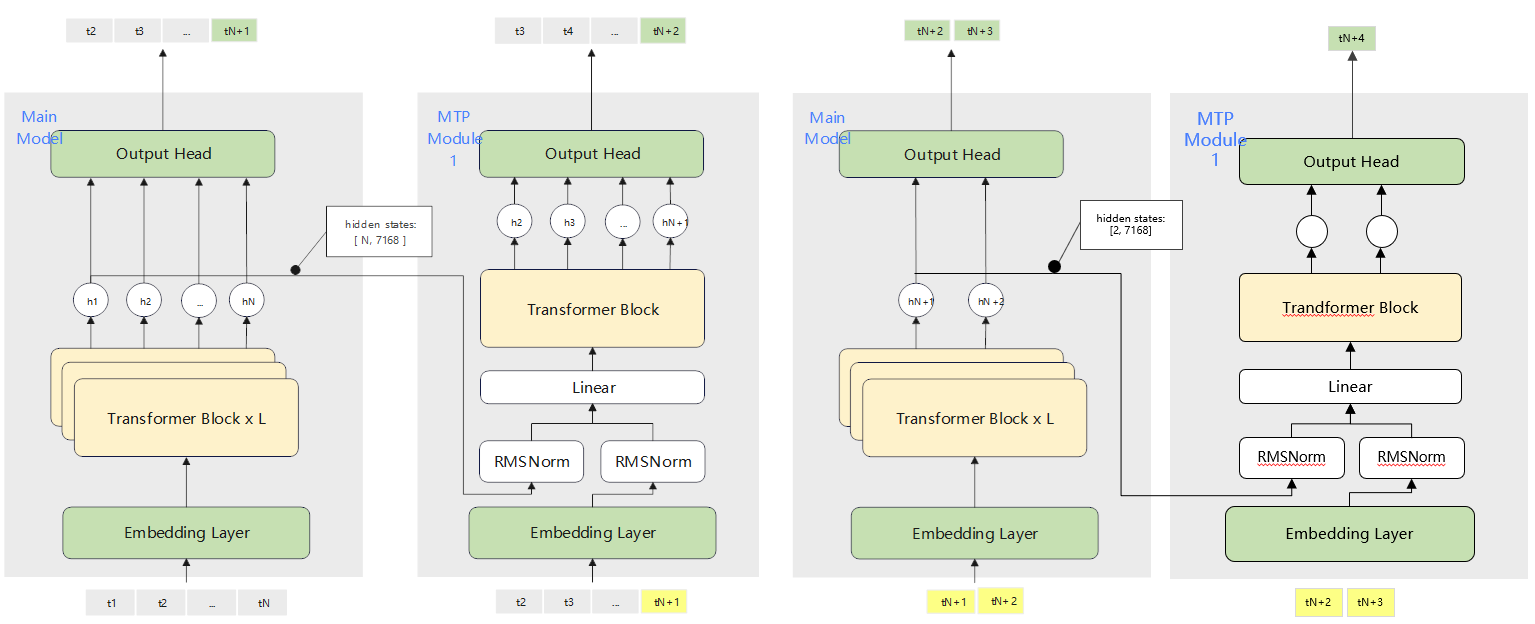
先主模型推理,输入的token是t1到tN,经过一轮推理之后,可以得到1个输出token tN+1,同时输出最后一层的hiddenstates。之后进行MTP层推理,MTP层的输入token是将主模型的prefilltokens进行roll操作,从t2开始输入,最后拼接上主模型输出的token tN+1。经过1轮推理得到草稿token tN+2。获得草稿token tN+2之后,我们将上一轮主模型输出的token tN+1和草稿token tN+2拼接,一起输入给主模型进行推理,得到token tN+2和token tN+3. 之后继续将输入token tN+1和草稿token tN+2的最后一层的hiddenstates和token tN+2和token tN+3输入给MTP层,得到新的草稿token,往后依次类推。
使能方法¶
在服务化的config.json文件中的ModelDeployConfig中的ModelConfig里新增如下字段(以MTP=1为例)
其中num_speculative_tokens表示MTP开启时每一轮猜测草稿token个数。
推理流程示例¶
以MTP=2为例,给出每一轮推理的具体流程
prefill阶段¶
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|----------------------|
|target model | input | input_ids | A | B | C | D |
| | | slot | 0 | 1 | 2 | 3 |
| | | position | 0 | 1 | 2 | 3 |
| | | context length | 4 | | | |
| | | lm head indices | 3 | | | |
| |--------------|----------------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | E | | | |
| | | output_hiddenstates | hiddenstates(ABCD) | | | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|----------------------|
|mtp | input | input_ids | B | C | D | E |
| | | slot | 0 | 1 | 2 | 3 |
| | | position | 0 | 1 | 2 | 3 |
| | | context length | 4 | | | |
| | | lm head indices | 3 | | | |
| | | hiddenstates | hiddenstates(ABCD) | | | |
| |--------------|----------------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | (ignore) | | | |
| | | output_hiddenstates | (ignore) | | | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|----------------------|
| | final output tokens | E | | | |
| | savehiddenstates | hiddenstates(D) | | | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|----------------------|
Prefill阶段的分别在主模型和MTP层(后续称小模型)进行prefill处理。 在主模型对输入的prompt ABCD完成推理后,会输出以ABCD为输入计算得到的中间结果hiddenstates(ABCD)。hiddenstates(ABCD)会作为小模型的输入。 同时,prefill的输出token E,会拼接成BCDE作为小模型的prompt进行一次prefill推理。以token E来说,mtp层输入了tokenE和对应的D的hiddenstates进行推理。至此,主模型和小模型均已包含完整的prompt的kvcache。
为了后续的decode的流程能够归一,我们先将这一轮输出的草稿token丢弃了,在decode阶段我们可以重新获取这个token
decode阶段¶
第一次decode¶
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
|mtp1 | input | input_ids | E | 0 | 0 |
| | | slot | 3 | 4 | 5 |
| | | position | 4 | 5 | 6 |
| | | context length | 6 | | |
| | | lm head indices | 0 | | |
| | | hiddenstates | hiddenstates(D00) | | |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | f | | |
| | | output_hiddenstates | hiddenstates_mtp(Exx)| | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
|mtp2 | input | input_ids | f | 0 | 0 |
| | | slot | 4 | 5 | 6 |
| | | position | 5 | 6 | 7 |
| | | context length | 7 | | |
| | | lm head indices | 0 | | |
| | | hiddenstates | hiddenstates_mtp(Exx)| | |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | g | | |
| | | output_hiddenstates | (ignore) | | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
|target model | input | input_ids | E | f | g |
| | | slot | 4 | 5 | 6 |
| | | position | 4 | 5 | 6 |
| | | context length | 7 | | |
| | | lm head indices | 0 | 1 | 2 |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | F | x | x |
| | | output_hiddenstates | hiddenstates(Efg) | | |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | verify | accept tokens | F | | |
| | 校验未命中 | savehiddenstates | hiddenstates(E) | | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
Decode阶段的推理流程类似大小模型投机推理,先进行小模型推理,再进行大模型推理: ① 小模型(MTP层)推理输出草稿token ② 草稿token拼接给大模型输入得到推理结果 ③ 校验verify操作进行token-by-token的比对,判断可接受的token数
对于第一次decode,将prefill输出的token E作为小模型的输入,这里为了处理方便,会将小模型的输入长度pad到num_speculative_tokens + 1个,hiddenstates使用的是prefill最后一个token D的hiddenstates,并pad到num_speculative_tokens + 1的shape,多轮MTP shape一致。
【说明】PD分离的场景,D节点无法获取到正确的P输出的hiddenstates,这里会用全0代替。而第一轮MTP需要的kv cache在P节点已经计算好并pull kv到了D节点,因此第一次decode中的第一层mtp不需要save kv cache。当前实现使用存到dummy blocktable的方式实现,保证正确的kvcache不被污染
非第一次decode¶
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
|mtp1 | input | input_ids | F | 0 | 0 |
| | | slot | 4 | 5 | 6 |
| | | position | 5 | 6 | 7 |
| | | context length | 7 | | |
| | | lm head indices | 0 | | |
| | | hiddenstates | hiddenstates(E00) | | |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | G | | |
| | | output_hiddenstates | hiddenstates_mtp(Fxx)| | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
|mtp2 | input | input_ids | G | 0 | 0 |
| | | slot | 5 | 6 | 7 |
| | | position | 6 | 7 | 8 |
| | | context length | 8 | | |
| | | lm head indices | 0 | | |
| | | hiddenstates | hiddenstates_mtp(Fxx)| | |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | H | | |
| | | output_hiddenstates | (ignore) | | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
|target model | input | input_ids | F | G | H |
| | | slot | 5 | 6 | 7 |
| | | position | 5 | 6 | 7 |
| | | context length | 8 | | |
| | | lm head indices | 0 | 1 | 2 |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | output | output_tokenid | I | x | x |
| | | output_hiddenstates | hiddenstates(FGH) | | |
| |--------------|----------------------|----------------------|----------------------|----------------------|
| | verify | accept tokens | I | | |
| | 校验全命中 | savehiddenstates | hiddenstates(FGH) | | |
|---------------|--------------|----------------------|----------------------|----------------------|----------------------|
对于后续的decode,第一层MTP层的输入即为上一轮decode中主模型的输出pad到num_speculative_tokens + 1得到,hidden states类似。每一轮MTP层的输入长度都是num_speculative_tokens + 1,为复用lm_head_indice的值,每轮MTP的输入均为上一轮MTP的输入向左roll一位后,将上一轮MTP输出的token换到lm_head_indice的位置上。slots、position_id做相应的更新。 主模型则是将MTP层输出的多个草稿token拼入输入的input_ids中。因此无论MTP层还是主模型,输入的shape是一致的,每个bs的长度都是num_speculative_tokens + 1。
token-by-token比对的verify方法¶
verify的目的是保证在开启和关闭MTP时能保证精度完全无损,即开启MTP时和自回归的输出一致。
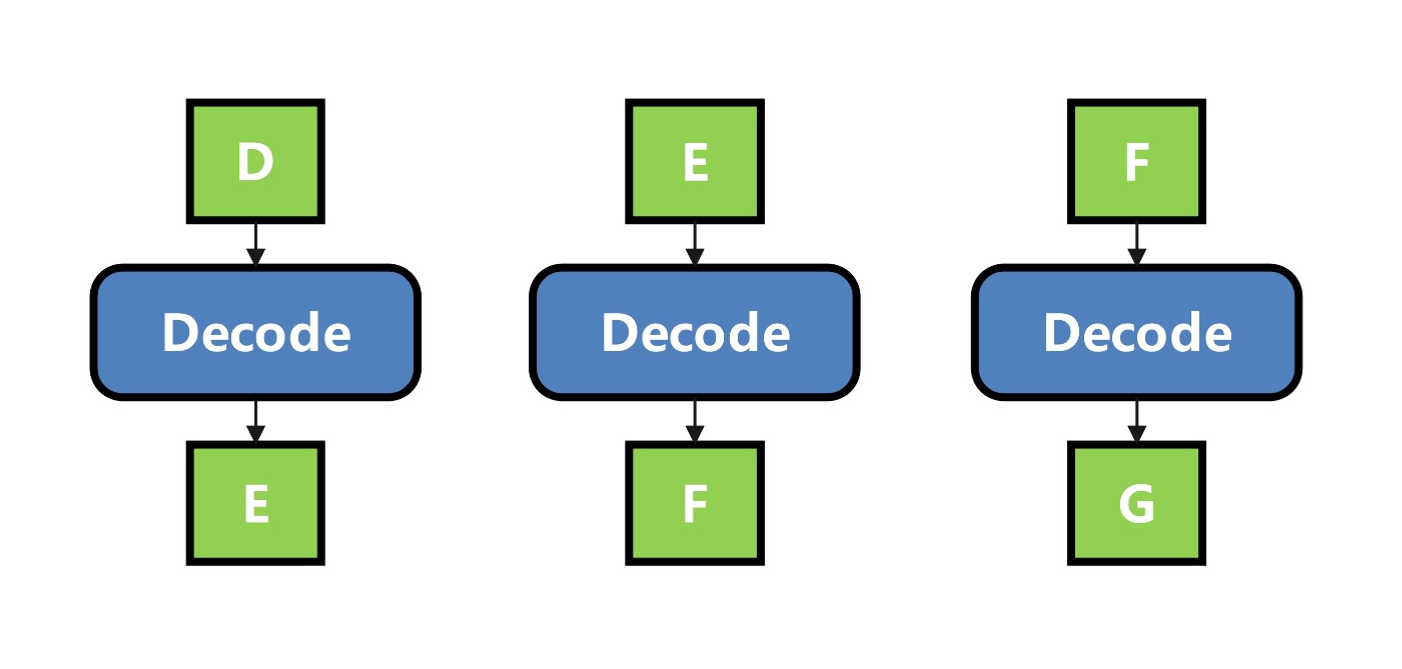
按自回归的推理,如下图所示,由token D推理得到E,由E推理得到F,以此类推。
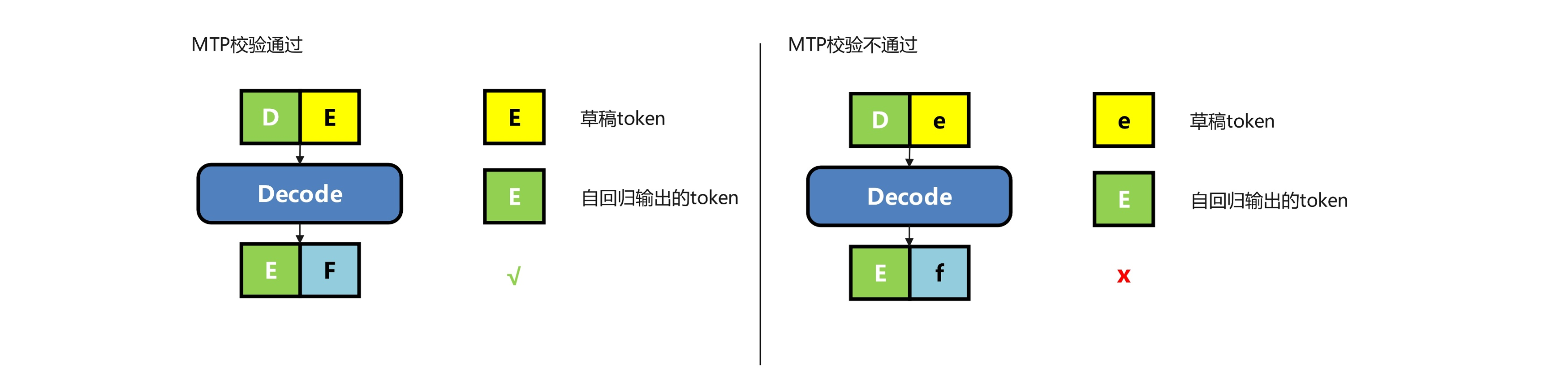
对于MTP开启的场景,如下图所示,需要比对草稿E和由D输出的自回归的tokenE是否是相同的。如果相同,就意味着由草稿E得到的tokenF也是正确的。反之,如果不相等,说明由这个草稿token e推理得到的f就是错误的,所以不可以接收这个token。
代码调用流程图示¶
以集中式、同步调度场景为例(分布式省去generator torch中的dp切分和padding计算),给出MindIE_LLM仓中MTP的代码运行流程。
模块间输入输出参数汇总¶
plugin_manager与generator_torch¶
输入参数¶
prefill阶段¶
model_inputs(host,np数组):主模型的输入
【说明】prefill阶段只需要构造主模型的输入,草稿模型的输入除input_ids外与主模型完全一致,因此在flash_causal_deepseekv2.py文件中,在主模型执行完成后,更新input_ids,草稿模型可直接复用主模型输入,无需额外构造。
decode阶段¶
- model_inputs(host,np数组):主模型的输入,其中每个batchsize固定输入
num_speculative_tokens + 1个token,input_ids中空出草稿token的位置。 - sub_model_inputs(host,np数组):MTP层的输入,结构与model_inputs一致。MTP>1时,也只有一份sub_model_inputs,多轮MTP之间的参数更新承载在flash_causal_deepseekv2文件中。
- q_lens(List):表示每个bs的输入token个数,当前场景固定由bs个
num_speculative_tokens + 1的值构成的1维List - hidden_states(host,torch.tensor):上一轮主模型输出的hidden_states,shape为
[(num_speculative_tokens + 1) *bs,hidden_size]
[说明] 当MTP>1时,对于小模型来说,每增加一层MTP推理,就需要增加一个slot存放新增的kv cache,因此在sub_model_inputs中的slots的个数是有可能大于输入input_ids的个数的。slots的shape为[1,bs * mtp * 2]。之后在flash_causal_deepseekv2.py文件中,会将slots切分成每一层推理时需要的slots,最终每一层mtp拿到的slots的shape依旧是[1,bs * (num_speculative_tokens + 1)]
输出参数¶
此处的输出参数是从flash_causal_deepseekv2.py中透传得到的。
prefill阶段¶
- logits(device,torch.tensor):主模型的输出
- hidden_states(device,torch.tensor):主模型最后一层的hidden_states,此处只输出最后一个token的hiddenstates,shape为
[1 *bs,hidden_size]
decode阶段¶
- logits(device,torch.tensor):主模型的输出
- hidden_states(device,torch.tensor):主模型最后一层的hidden_states,shape为
[(num_speculative_tokens + 1) *bs,hidden_size] - draft_tokens(device,torch.tensor):格式为
[batch0 (draft_token0~num_speculative_tokens-1) batch1 ...batch2...]
generator_torch 与 flash_causal_deepseekv2¶
输入参数¶
- sub_model_inputs(device,torch.tensor):小模型model_inputs,仅decode阶段存在
- lm_head_local_dp:仅集中式有,MTP>1时使用,用于每一轮小模型输入token更新的indice位置
- q_lens:1维list,表示每个bs的输入token个数,集中式时此处是经过dp切分的qlen,分布式时是plugin_manager透传得到
输出参数¶
同plugin_manager与generator_torch数据接口的输出参数。
代码实现¶
主要流程¶
MTP流程中的主要新增代码承载在以下文件中:
-
mtp_plugin.py & decoding_policy.py
mtp_plugin.py文件由plugin_manager.py文件调用,在主调度流程中,调用mtp的以下功能:
① 基于自回归时的基础模型输入,构造mtp场景下主模型和草稿模型需要的模型输入;
② 采样参数构造;
③ mtp场景每轮decode需要缓存的信息管理;
④ 对草稿token的校验处理(当前仅支持token比对);
⑤ 叠加异步调度时的模型输入参数更新。
-
flash_causal_deepseekv2.py的入口函数是 forward()方法,调用顺序:
plugin_manager.py(generate_token() or generate_token_async())--> generator_torch.py(forward()) --> atb_model_wrapper.py (forward())--> flash_causal_deepseekv2.py(forward())
① mtp prefill和decode的入口函数;
② 承载多轮草稿模型之间、草稿模型与主模型之间的模型输入更新。
③ mtp的权重加载(初始化时调用)
-
承载草稿模型的组图
MTP适配集中式场景下的dp并行¶
在集中式场景下的dp的数据流如下(以同步场景为例):
input_metadata ← 所有dp的seq数据,无陪跑(host)
↓
+------------------------+
| plugin_manager | ← 生成 model_inputs、qlen、mask、hiddenstates
+------------------------+
↓
model_inputs
qlen、mask、hiddenstates ← 所有dp的seq数据,无陪跑(host)
↓
+------------------------+
| generator_torch | ← dp切分,仅保留当前dp组的seq模型输入,构造陪跑
+------------------------+
↓
model_inputs
qlen、mask、hiddenstates ← 当前卡所在dp的seq模型输入(host)
其他模型输入的参数
↓
+------------------------+
| atb_model_wrapper | ← 模型输入H2D
+------------------------+
↓
当前dp组模型输入参数 ← 模型输入(device)
↓
+------------------------+
| model_runner.forward | ← 模型执行
+------------------------+
↓
模型执行结果输出
logits、hiddenstates ← 所有dp的seq数据,无陪跑(device)
draft_tokens
代码适配点¶
适配函数位置:generator_torch.py
-
qlen、mask的适配: 抽取当前dp组的qlen和mask,对于当前dp组没有数据的情况,构造的陪跑数据使用qlen = 1,mask仅1行。
-
lm_head_indice的适配:
lm_head_indice在集中式场景下包含将陪跑数据剔除的功能。实现函数名:
_partition_data① MTP层lm_head_indice:
以MTP=3为例,MTP层的输入是每个seq 4个token,最终需要的logits输出位置与前一轮输出了几个token有关。举例如下:
假设当前4个bs,4个dp组
|-----------------|-------------------|-------------------|-------------------|-------------------| | batch | bs1 | bs2 | bs3 | bs4 | | input_ids | A1 | A2 | A3 | A4 | B1 | B2 | B3 | B4 | C1 | C2 | C3 | C4 | D1 | D2 | D3 | D4 | | dp_rank_ids | 0 | 0 | 2 | 3 | | last_output_len | 4 | 2 | 1 | 3 | | total_indice | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | | lm_head_indice | 3 | 5 | 8 | 14 | |-----------------|-------------------|-------------------|-------------------|-------------------|该示例中,缺少dp_rank_id = 1的情况,即dp1上会存在陪跑。目前陪跑只输入1个token,即qlen=1,因此dp组收齐时拿到的结果如下:
|-----------------|-------------------|-------------------|-------|-------------------|-------------------| | batch | bs1 | bs2 | dummy | bs3 | bs4 | | input_ids | A1 | A2 | A3 | A4 | B1 | B2 | B3 | B4 | 1 | C1 | C2 | C3 | C4 | D1 | D2 | D3 | D4 | | dp_rank_ids | 0 | 0 | 1 | 2 | 3 | | last_output_len | 4 | 2 | - | 1 | 3 | | total_indice | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |-----------------|-------------------|-------------------|-------|-------------------|-------------------|在dummy存在的情况下,为了保证抽取的输出位置依旧正确,lm_head_indice需要修改为:
[3, 5, 9, 15]② 主模型lm_head_indice: 由于主模型的输出是所有token都需要,所以初始lm_head_indice是全量保留,即
np.arange(len(input_ids)), 陪跑逻辑与小模型相同,在有dummy时更新即可。[注] 当前lm_head_indice的适配支持dp_rank_ids分布乱序,但目前实际不会出现乱序的情况,可做进一步优化。
-
lm_head_local_dp的计算:
功能:由于每一轮小模型MTP层推理前都需要更新input_ids,即roll一次input_ids后再将新的token更新进input_ids中。但此时在forward中的input_ids是仅当前dp组的input_ids,所以需要有一个针对当前dp组input_ids更新token的位置indice。
实现函数名:
_lm_head_local_dp_calc继续沿用2中给出的例子,以dp4为例说明:
dp0的mtp1输入:
```json input_ids : A1 A2 A3 A4 B1 B2 B3 B4 lm_head_indice : [3, 5, 9, 15] ```dp4的mtp2输入:(根据last_output_len长度替换对应的token)
```json input_ids : A2 A3 A4 A5 B2 B5 B4 x lm_head_indice : [3, 5, 9, 15] ```因此dp0上需要的lm_head_local_dp的值为[3, 5]
同理,dp1是陪跑,lm_head_local_dp的值为[0],dp2为[0],dp3为[2]
[注] 当前lm_head_local_dp的适配支持dp_rank_ids分布乱序,但目前实际不会出现乱序的情况,可做进一步优化。
MTP适配异步调度¶
异步调度场景,从batch_context中获取的缓存结果可能会少一轮推理的结果,因此在前处理后得到的模型输入参数,需要在最终入队input队列之前,基于最新的输出结果进行更新。
但是并非所有请求的参数都需要更新,只有上一轮也调度到的请求才需要,因此需要提前计算好需要更新的请求的位置,用hit_mask选出需要更新的请求。
代码适配点¶
-
适配点1:
hit_mask计算实现函数:prepare_masks_for_filling(文件位置:../../../../mindie_llm/text_generator/plugins/mtp/mtp_plugin.py)
功能:根据当前轮的seq id是否存在和前一轮调度的seq id一致,来挑选出需要更新的请求。
-
适配点2:模型输入参数更新
实现函数:fill_in_model_result(文件位置:../../../../mindie_llm/text_generator/plugins/mtp/mtp_plugin.py)
功能:由于input_ids、slots、position ids、context_length、lm_head_indice均和上一轮输出的结果有关,因此需要单独更新。