多模态理解模型迁移适配指南¶
简介¶
本章节适用于底座大语言模型已经在MindIE LLM模型仓中适配,需要新增适配多模态理解模型所依赖的多模态Encoder模型(如视觉理解中的ViT模型)。
我们适配多模态Encoder模型时,需要实现如下四个主要的类,其余依赖方法可自行设计。
入口端适配的类为:
{llm_path}/examples/models/{model}/run_pa.py(_{model}_Runner)
模型端适配的类为:
{llm_path}/atb_llm/models/{model}/router_{model}.py(_{model}_Router)
{llm_path}/atb_llm/models/{model}/config_{model}.py (_{model}_Config)
{llm_path}/atb_llm/models/{model}/flash_causal_{model}.py (_{model}_Flash{model}ForCausalLM)
其中,{llm_path}为模型仓所在路径:
- 若使用编译好的包,则路径为“ ${working_dir}/MindIE-LLM/”。
- 若使用gitee下载的代码,则路径为 “${working_dir}/MindIE-LLM/examples/atb_models”。
入口端适配¶
入口端适配中,我们需要在“{llm_path}/examples/models/{model}”路径下,构建一个run_pa.py脚本,该脚本构建一个继承了基类MultimodalPARunner的子类_{model}_Runner。该子类实现如下功能:
- 调用_{model}Router、{model}Config、Flash{model}_ForCausalLM实现模型配置和模型权重的加载。
- 实现模型的warm_up和前向推理。
如有需要,重写对应函数或方法即可。
输入类型¶
推理接口接收的输入类型如下:
@dataclass
class MultimodalInput:
input_texts:List | None
image_path:List | None
video_path:List | None
audio_path:List | None
-
“input_texts”类型为“List[str]”或者“List[dict]”,以InternVL2.5为例,其输入的input_texts可以为:
[{'role': 'user', 'content': 'Write an essay about this image, at least 256 words.'}]或['Write an essay about this image, at least 256 words.']
-
“image_path”、“video_path”、“audio_path”这三个参数对应路径列表,存放相应模态数据的路径。以图片“image_path”为例,这里必须存放每张图片的对应路径,而不能是目录。
以InternVL2.5模型接收图片和文本作为输入为例:
如果同时推理多张图,需将每张图的路径解析出来存放到MultimodalInput.image_path对应的变量中。模型推理的时候,会将“input_texts”中的第一个元素和“image_path”中的第一个元素作为一组输入进行推理,“input_texts”中的第二个元素和“image_path”中的第二个元素作为第二组输入进行推理,依次类推,满足一一对应关系。
初始化及warm_up¶
初始化在大部分情况下可以直接调用基类MultimodalPARunner的初始化完成,子类仅需要完成相应属性或方法的初始化。
以InternVL2.5示例如下:
class InternvlRunner(MultimodalPARunner):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.pred_file = PRED_FILE
def init_processor(self):
self.processor = self.model.tokenizer
模型warm_up过程是直接使用输入的第一组参数进行推理,如无定制参数,则warm_up方法无需重写。
前向推理¶
对于前向推理部分,需要额外提供一个最大迭代次数“max_iters”参数。由于每个模型计算“max_iters”参数的方式存在区别,因此,前向推理的infer函数必须在子类中重写或者提前计算好该参数。如果在子类中重写infer函数,请务必保证输入的参数格式与基类的infer完全一致,计算得到该参数后,再调用super().infer()来执行父类中的infer函数逻辑。
示例如下:
```python
def infer(self, mm_inputs, batch_size, max_output_length, ignore_eos, max_iters=None, **kwargs):
input_texts = mm_inputs.input_texts
image_path_list = mm_inputs.image_path
video_path_list = mm_inputs.video_path
path_list = image_path_list if image_path_list else video_path_list
if len(input_texts) != len(image_path_list):
raise RuntimeError("input_text length must equal input_images length")
if not ENV.profiling_enable:
if self.max_batch_size > 0:
max_iters = math.ceil(len(mm_inputs.image_path) / self.max_batch_size)
else:
raise RuntimeError("f{self.max_batch_size} max_batch_size should > 0, please check")
return super().infer(mm_inputs, batch_size, max_output_length, ignore_eos, max_iters=max_iters)
```
- 如果有四种模态(文本、图像、音频或视频)输入之外的其他定制参数,则需要重写“prepare_request”函数,可参考_{llm_path}_/examples/models/multimodal_runner.py中“prepare_request”函数的实现。
-
如果需要对精度测试结果进行保存,则需要在子类中重写precision_save方法来保存结果。示例如下:
def precision_save(self, precision_inputs, **kwargs): all_input_texts = precision_inputs.all_input_texts all_generate_text_list = precision_inputs.all_generate_text_list image_file_list = precision_inputs.image_file_list video_file_list = precision_inputs.video_file_list file_list = image_file_list if image_file_list else video_file_list answer_pairs = {} if not file_list: raise ValueError("Both image_file_list and video_file_list are empty.") if len(all_input_texts) != len(file_list): raise ValueError(f"Mismatched lengths between \ all_input_texts={all_input_texts} and file_list={file_list}") for text_index in range(len(all_input_texts)): image_answer_pairs[file_list[text_index]] = all_generate_text_list[text_index] image_answer_pairs = dict(sorted(answer_pairs.items())) super().precision_save(precision_inputs, answer_pairs=answer_pairs)
Main函数实现样例¶
通过继承或者重写初始化、warm_up以及前向推理等方法,实现了适配基类“MultimodalPARunner”后,需要在Main函数中实现基本的路径解析和输入准备,以InternVL2.5为例:
if __name__ == '__main__':
args = parse_arguments()
rank = ENV.rank
local_rank = ENV.local_rank
world_size = ENV.world_size
image_or_video_path = standardize_path(args.image_or_video_path)
check_file_safety(image_or_video_path, 'r')
file_name = safe_listdir(image_or_video_path)
file_length = len(file_name)
input_dict = {
'rank': rank,
'world_size': world_size,
'local_rank': local_rank,
'perf_file': PERF_FILE,
**vars(args)
}
if is_image_path(image_or_video_path):
image_path = [os.path.join(image_or_video_path, f) for f in file_name]
video_path = None
input_dict['image_path'] = image_path
texts = args.input_texts_for_image
elif is_video_path(image_or_video_path):
video_path = [os.path.join(image_or_video_path, f) for f in file_name]
image_path = None
input_dict['video_path'] = video_path
texts = args.input_texts_for_video
else:
logger.error("Unsupported media type, it should be a video or image, please check your input.", ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise KeyError("Unsupported media type, it should be a video or image, please check your input.")
if len(texts) > file_length:
raise ValueError(f"The number of input texts is greater than the number of files.")
texts.extend([texts[-1]] * (file_length - len(texts)))
input_dict['input_texts'] = texts
pa_runner = InternvlRunner(**input_dict)
if image_path:
image_length = len(image_path)
remainder = image_length % args.max_batch_size
if remainder != 0:
num_to_add = args.max_batch_size - remainder
image_path.extend([image_path[-1]] * num_to_add)
texts.extend([texts[-1]] * num_to_add)
elif video_path:
video_length = len(video_path)
remainder = video_length % args.max_batch_size
if remainder != 0:
num_to_add = args.max_batch_size - remainder
video_path.extend([video_path[-1]] * num_to_add)
texts.extend([texts[-1]] * num_to_add)
print_log(rank, logger.info, f'pa_runner: {pa_runner}')
infer_params = {
"mm_inputs": MultimodalInput(texts,
image_path,
video_path,
None),
"batch_size": args.max_batch_size,
"max_output_length": args.max_output_length,
"ignore_eos": args.ignore_eos,
}
pa_runner.warm_up()
generate_texts, token_nums, latency = pa_runner.infer(**infer_params)
for i, generate_text in enumerate(generate_texts):
print_log(rank, logger.info, f'Answer[{i}]: {generate_text}')
print_log(rank, logger.info, f'Generate[{i}] token num: {token_nums[i]}')
print_log(rank, logger.info, f"Latency: {latency}")
模型端适配¶
模型端适配中,我们需要适配_{model}Router,{model}Config和Flash{model}_ForCausalLM三个类。
_{model}_Router类适配¶
MultimodalPARunner调用“{llm_path}/atb_llm/models/{model}/router_{model}.py”中的_{model}Router进行模型的初始化及配置文件的加载,其中{model}_为模型名,需要严格与模型配置文件中的“model_type”保持一致。
_{model}_Router类起到路由的作用,告诉模型加载哪里的模型和对应的配置文件。
_{model}_Router类继承于基类BaseRouter,对于模型迁移适配,该类需要实现的方法有:“get_config”和“get_tokenizer”。
- “get_config”是从模型权重的“config.json”中加载相关参数并初始化模型的config类。
- “get_tokenizer”是初始化tokenizer。
示例如下:
from ..base.router import BaseRouter
@dataclass
class InternvlRouter(BaseRouter):
def get_config(self):
config = InternvlConfig.from_pretrained(self.model_name_or_path)
if self.max_position_embeddings:
config.max_position_embeddings = self.max_position_embeddings
config.model_name_or_path = self.model_name_or_path
super().check_config(config)
return config
def get_tokenizer(self):
try:
llm_model_architectures = self.config_dict['llm_config']['architectures'][0]
except KeyError as e:
logger.error("`llm_config.architectures` does not exist! Check `config.json`.",
ErrorCode.ATB_MODELS_MODEL_PARAM_JSON_INVALID)
raise ValueError("`llm_config.architectures` does not exist! Check `config.json`.") from e
if llm_model_architectures == INTERNLM2_ARCHITECTURE:
tokenizer = safe_get_tokenizer_from_pretrained(
self.model_name_or_path,
trust_remote_code=self.trust_remote_code
)
elif llm_model_architectures == LLAMA_ARCHITECTURE:
tokenizer = safe_get_tokenizer_from_pretrained(
self.model_name_or_path,
revision=self.revision,
padding_side="left",
trust_remote_code=self.trust_remote_code,
use_fast=False
)
elif llm_model_architectures == QWEN2_ARCHITECTURE:
tokenizer = safe_get_tokenizer_from_pretrained(
self.model_name_or_path,
padding_side="left",
trust_remote_code=self.trust_remote_code,
)
else:
logger.error(
"`llm_config.architectures` must in "
f"[{LLAMA_ARCHITECTURE}, {INTERNLM2_ARCHITECTURE}, {QWEN2_ARCHITECTURE}], "
f"got {llm_model_architectures}.",
ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise ValueError(
"`llm_config.architectures` must in "
f"[{LLAMA_ARCHITECTURE}, {INTERNLM2_ARCHITECTURE}, {QWEN2_ARCHITECTURE}], "
f"got {llm_model_architectures}.")
return tokenizer
def get_input_builder(self):
return InternvlInputBuilder(self.tokenizer, self.config)
def tokenize(self, inputs, **kwargs):
img_begin_id = self.tokenizer.encode("<img>")[-1]
img_end_id = self.tokenizer.encode("</img>")[-1]
shm_name_save_path = kwargs.get("shm_name_save_path", None)
image_size = self.config.force_image_size or self.config.vision_config.image_size
patch_size = self.config.vision_config.patch_size
if patch_size == 0:
logger.error('The vision patch_size of config can not be 0.',
ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise ValueError('The vision patch_size of config can not be 0.')
num_image_token = int((image_size // patch_size) ** 2 * (self.config.downsample_ratio ** 2))
use_dynamic_prepro = False if self.config.ps_version == "v1" else True
system_prompt = INTERNVL_SYSTEM_PROMPTS[self.config.ps_version][self.config.template]
query = ('<|im_start|>system\n'
f'{system_prompt}<|im_end|><|im_start|>user\n')
text = ""
image_index = 1
shm_name_list = []
shape_value_list = []
image_num = sum(1 for d in inputs if _IMAGE in d)
for single_input in inputs:
if _TEXT in single_input:
text += single_input.get(_TEXT)
continue
if _IMAGE in single_input:
current_query, shm_name_value, shape_value = process_image_input(
single_input,
image_num,
image_index,
use_dynamic_prepro,
num_image_token,
shm_name_save_path
)
query += current_query
image_index += 1
shm_name_list.append(shm_name_value)
shape_value_list.append(shape_value)
elif _VIDEO in single_input:
current_query, shm_name_value, shape_value = process_video_input(
single_input,
use_dynamic_prepro,
num_image_token,
shm_name_save_path
)
query += current_query
shm_name_list += shm_name_value
shape_value_list += shape_value
else:
logger.error("Unsupported media type, it should be a video or image, please check your input.",
ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise KeyError("Unsupported media type, it should be a video or image, please check your input.")
query += f'{text}<|im_end|><|im_start|>assistant\n'
query_ids = torch.tensor(self.tokenizer.encode(query))
bos_pos_set = torch.nonzero(query_ids == img_begin_id).view(-1)
eos_pos_set = torch.nonzero(query_ids == img_end_id).view(-1)
for i, (bos_pos, eos_pos) in enumerate(zip(bos_pos_set, eos_pos_set)):
if eos_pos - bos_pos < 3:
logger.error("tokenize input error.",
ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise ValueError("tokenize input error.")
query_ids[bos_pos + 1] = shm_name_list[i]
query_ids[bos_pos + 2] = shape_value_list[i]
return query_ids
_{model}_Config类适配¶
{model}_Config类实现模型配置参数的加载,用于初始化模型。它位置不固定,可置于“{llm_path}/atb_llm/models/{model}/flash_causal_{model}.py”文件或为独立文件“{llm_path}/atb_llm/models/{model}/config_{model}_.py”。
以InternVL2.5示例如下:
from dataclasses import dataclass
from atb_llm.models.base.config import BaseConfig
from atb_llm.models.internvl.config_intern_vit import InternVisionConfig
from atb_llm.models.internvl.flash_causal_internvl import INTERNLM2_ARCHITECTURE, LLAMA_ARCHITECTURE, QWEN2_ARCHITECTURE
from atb_llm.models.internlm2.v2.config_internlm2 import Internlm2Config
from atb_llm.models.llama.config_llama import LlamaConfig
from atb_llm.models.qwen2.config_qwen2 import Qwen2Config
from atb_llm.utils.log.error_code import ErrorCode
from atb_llm.utils.log.logging import logger
@dataclass
class InternvlConfig(BaseConfig):
model_type = 'internvl_chat'
is_composition = True
def __init__(self,
vision_config=None,
llm_config=None,
use_backbone_lora=0,
use_llm_lora=0,
select_layer=-1,
force_image_size=None,
downsample_ratio=0.5,
template=None,
dynamic_image_size=False,
use_thumbnail=False,
ps_version='v1',
min_dynamic_patch=1,
max_dynamic_patch=12,
**kwargs):
llm_config["quantize"] = None
llm_config["quantization_config"] = None
super().__init__(**llm_config)
self.vision_config = InternVisionConfig(**vision_config)
llm_model_architectures = llm_config['architectures'][0]
if llm_model_architectures == INTERNLM2_ARCHITECTURE:
self.llm_config = Internlm2Config(**llm_config)
elif llm_model_architectures == LLAMA_ARCHITECTURE:
self.llm_config = LlamaConfig(**llm_config)
elif llm_model_architectures == QWEN2_ARCHITECTURE:
self.llm_config = Qwen2Config(**llm_config)
else:
error_msg = (f"{llm_model_architectures} is an unsupported architecture, "
"check llm_config['architectures'] in config.json, "
"currently only InternLM2ForCausalLM, LlamaForCausalLM and Qwen2ForCausalLM are supported.")
logger.error(error_msg, ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise ValueError(error_msg)
self.use_backbone_lora = use_backbone_lora
self.use_llm_lora = use_llm_lora
self.select_layer = select_layer
self.force_image_size = force_image_size
self.downsample_ratio = downsample_ratio
self.template = template
self.dynamic_image_size = dynamic_image_size
self.use_thumbnail = use_thumbnail
self.ps_version = ps_version # pixel shuffle version
self.min_dynamic_patch = min_dynamic_patch
self.max_dynamic_patch = max_dynamic_patch
Flash_{model}_ForCausalLM类适配¶
Flash_{model}ForCausalLM类实现了模型的初始化、权重加载以及前向推理,位于“{llm_path}/atb_llm/models/{model}/flash_causal_{model}_.py”文件。
以InternVL2.5为例如下:
from ..base.flash_causal_multimodal import MultiModalLLm
class FlashInternvlForCausalLM(FlashForCausalLM):
def __init__(self, config, weights, **kwargs):
super().__init__(config, weights, **kwargs)
self.config = config
self.trust_remote_code = kwargs.get('trust_remote_code', False)
self.weights = weights # id相等,引用传递
self.dtype = weights.dtype
self.vision_config = config.vision_config
enable_vit_dp = kwargs.get('enable_vit_dp', True)
setattr(self.vision_config, 'enable_vit_dp', enable_vit_dp)
self.llm_config = config.llm_config
self.llm_config.quantize = None
# 图片处理相关参数
self.downsample_ratio = config.downsample_ratio
self.vit_hidden_size = self.vision_config.hidden_size
self.llm_hidden_size = self.llm_config.hidden_size
self.image_size = config.force_image_size or self.vision_config.image_size
self.patch_size = self.vision_config.patch_size
self.select_layer = config.select_layer
self.num_image_token = int((self.image_size // self.patch_size) ** 2 * (self.downsample_ratio ** 2))
self.neftune_alpha = None
self.im_mask = None
self.template = config.template
self.ps_version = config.ps_version
if self.template not in ['Hermes-2', 'internlm2-chat', 'phi3-chat', 'internvl2_5']:
raise ValueError(
f"Unsupported template {self.template}, supported templates are `Hermes-2`, "
"`internlm2-chat`, `phi3-chat`, `internvl2_5`. Please check the value of 'template' in config.json"
)
if self.ps_version not in ['v1', 'v2']:
raise ValueError(
f"Unsupported ps_version {self.ps_version}, supported templates are `v1` and `v2`."
"Please check the value of 'ps_version' in config.json"
)
self.npu_id = weights.device.index
self.process_group, self.device = initialize_torch_distributed(self.tp_rank, self.npu_id, self.tp_world_size)
self.init_llm_model_type()
self.init_vision_model()
self.init_mlp_projector()
self.init_language_model()
self.init_normalizer()
if self.llm_model_type == ACTION_INTERNLM2:
if self.dtype != torch.float16:
logger.error(
f"{self.dtype} is unsupported, supported dtypes are float16."
"Please check the value of 'torch_dtype' in config.json",
ErrorCode.ATB_MODELS_MODEL_PARAM_JSON_INVALID
)
raise ValueError(
f"{self.dtype} is unsupported, supported dtypes are float16."
"Please check the value of 'torch_dtype' in config.json"
)
self.llm_embedding_layer = self.language_model.get_embedding_layer()
self.processor = safe_get_tokenizer_from_pretrained(
config.model_name_or_path, trust_remote_code=self.trust_remote_code
)
self.config.eos_token_id = INTERNLM2_EOS_TOKEN_ID
elif self.llm_model_type == ACTION_LLAMA:
self.llm_embedding_layer = self.language_model.model.embed_tokens
self.processor = safe_get_tokenizer_from_pretrained(
self.config.model_name_or_path, trust_remote_code=self.trust_remote_code, use_fast=False
)
self.config.eos_token_id = self.llm_config.eos_token_id
elif self.llm_model_type == ACTION_QWEN2:
self.llm_embedding_layer = self.language_model.transformer.wte
self.processor = safe_get_tokenizer_from_pretrained(
self.config.model_name_or_path, padding_side="left", trust_remote_code=self.trust_remote_code,
)
self.config.eos_token_id = self.llm_config.eos_token_id
self.img_begin_id = self.processor.encode("<img>")[-1]
self.img_end_id = self.processor.encode("</img>")[-1]
self.img_context_token_id = self.processor.encode("<IMG_CONTEXT>")[-1]
def init_module_weight(self, module, weights, prefix="model", prefixskip=None):
model_weights = [model_weight for model_weight in module.state_dict().keys()]
for model_weight in model_weights:
if prefixskip and prefixskip in model_weight:
continue
saved_weight = torch.nn.Parameter(
weights.get_tensor(f"{prefix}.{model_weight}"), requires_grad=False
)
if not self.vision_config.enable_vit_dp:
saved_weight = internvl_tensor_parallel_split(model_weight, prefix, \
self.tp_rank, self.tp_world_size, saved_weight)
model_weight_list = model_weight.split(".")
target_module = module
for nxt_module in model_weight_list[:-1]:
target_module = getattr(target_module, nxt_module)
setattr(target_module, model_weight_list[-1], saved_weight)
def init_llm_model_type(self):
llm_model_architectures = self.llm_config.architectures[0]
if llm_model_architectures == INTERNLM2_ARCHITECTURE:
self.llm_model_type = ACTION_INTERNLM2 # internlm: VL2-2B、VL2-8B、VL2-20B
elif llm_model_architectures == LLAMA_ARCHITECTURE:
self.llm_model_type = ACTION_LLAMA # llama, yi: VL2-40B、VL2-76B
elif llm_model_architectures == QWEN2_ARCHITECTURE:
self.llm_model_type = ACTION_QWEN2 # qwen: VL2-1B
else:
logger.error("Currently only InternVL-Chat-V1-2、InternVL-Chat-V1-5、InternVL2 are supported. "
"Please check `config.json`.",
ErrorCode.ATB_MODELS_MODEL_PARAM_JSON_INVALID)
raise KeyError("Currently only InternVL-Chat-V1-2、InternVL-Chat-V1-5、InternVL2 are supported. "
"Please check `config.json`.")
def init_normalizer(self):
weight, bias = create_standardization_params(IMAGENET_MEAN, IMAGENET_STD, RESCALE_FACTOR, CONV_CHANNELS)
self.normalizer = nn.Conv2d(in_channels=CONV_CHANNELS, out_channels=CONV_CHANNELS, kernel_size=1, \
groups=CONV_GROUPS)
self.normalizer.weight = nn.Parameter(data=weight, requires_grad=False)
self.normalizer.bias = nn.Parameter(data=bias, requires_grad=False)
self.normalizer.npu()
# Normalizer warmup
self.normalizer(torch.randn(MAX_NUM_PATCHES, CONV_CHANNELS, IMAGE_SIZE, IMAGE_SIZE, device='npu'))
def init_vision_model(self):
self.vision_model = InternVisionModel(self.vision_config, self.process_group).to(dtype=self.dtype)
self.init_module_weight(self.vision_model, self.weights, prefix="vision_model")
self.vision_model = self.vision_model.to(self.device)
def init_mlp_projector(self):
if self.downsample_ratio == 0:
raise ZeroDivisionError("Downsample ratio will be zero")
input_dim = self.vit_hidden_size * int(np.divide(1, self.downsample_ratio)) ** 2
if self.vision_config.enable_vit_dp:
self.mlp1 = nn.Sequential(
nn.LayerNorm(input_dim),
nn.Linear(input_dim, self.llm_hidden_size),
nn.GELU(),
nn.Linear(self.llm_hidden_size, self.llm_hidden_size)
).to(dtype=self.dtype)
else:
self.mlp1 = nn.Sequential(
nn.LayerNorm(input_dim),
ColumnLinear(input_dim, self.llm_hidden_size, gather_output=False, process_group=self.process_group),
nn.GELU(),
RowLinear(self.llm_hidden_size, self.llm_hidden_size, process_group=self.process_group)
).to(dtype=self.dtype)
self.init_module_weight(self.mlp1, self.weights, prefix="mlp1")
self.mlp1 = self.mlp1.to(self.device)
def init_language_model(self):
model_type = self.llm_model_type
if model_type == ACTION_INTERNLM2:
self.language_model = FlashInternlm2ForCausalLM(
self.config,
self.weights,
lmhead_prefix=LMHEAD_PREFIX.replace('lm_head', 'output'),
model_prefix=MODEL_PREFIX,
)
elif model_type == ACTION_LLAMA:
self.language_model = LlamaForCausalLM(
self.llm_config,
self.weights,
lmhead_prefix=LMHEAD_PREFIX,
model_prefix=MODEL_PREFIX,
)
elif model_type == ACTION_QWEN2:
self.language_model = FlashQwen2ForCausalLM(
self.llm_config,
self.weights,
lmhead_prefix=LMHEAD_PREFIX,
model_prefix=MODEL_PREFIX,
transformer_wte_parallel=False,
)
else:
logger.error(f"Currently only {LLAMA_ARCHITECTURE}、{INTERNLM2_ARCHITECTURE}、{QWEN2_ARCHITECTURE} "
"are supported. Please check `config.json`.",
ErrorCode.ATB_MODELS_MODEL_PARAM_JSON_INVALID)
raise KeyError(f"Currently only {LLAMA_ARCHITECTURE}、{INTERNLM2_ARCHITECTURE}、{QWEN2_ARCHITECTURE} "
"are supported. Please check `config.json`.")
self.language_model.skip_word_embedding = True
def pixel_shuffle(self, x, scale_factor=0.5):
n, w, h, c = x.size()
# N, W, H, C --> N, W, H * scale, C // scale
if scale_factor == 0:
raise ZeroDivisionError("Scale factor will be zero")
x = x.view(n, w, int(h * scale_factor), int(np.divide(c, scale_factor)))
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
x = x.permute(0, 2, 1, 3).contiguous()
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
if scale_factor == 0:
raise ZeroDivisionError("Scale factor will be zero")
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
int(np.divide(c, scale_factor * scale_factor)))
if self.ps_version == 'v1':
print_log(self.tp_rank, logger.warning,
"In ps_version 'v1', the height and width have not been swapped back, "
"which results in a transposed image.")
else:
x = x.permute(0, 2, 1, 3).contiguous()
return x
def noised_embed(self, vit_embeds, noise_alpha=5):
dims = torch.tensor(vit_embeds.size(1) * vit_embeds.size(2))
if dims == 0:
raise ZeroDivisionError("Dim of the tensor is zero")
mag_norm = np.divide(noise_alpha, torch.sqrt(dims))
noise = torch.zeros_like(vit_embeds).uniform_(-mag_norm, mag_norm)
return vit_embeds + noise
def extract_feature(self, pixel_values):
if self.select_layer == -1:
vit_embeds = self.vision_model(
pixel_values=pixel_values,
output_hidden_states=False,
return_dict=True).last_hidden_state
else:
vit_embeds = self.vision_model(
pixel_values=pixel_values,
output_hidden_states=True,
return_dict=True).hidden_states[self.select_layer]
vit_embeds = vit_embeds[:, 1:, :]
if self.training and self.neftune_alpha is not None:
vit_embeds = self.noised_embed(vit_embeds, self.neftune_alpha)
h = w = int(vit_embeds.shape[1] ** 0.5)
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1)
vit_embeds = self.pixel_shuffle(vit_embeds, scale_factor=self.downsample_ratio)
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], -1, vit_embeds.shape[-1])
vit_embeds = self.mlp1(vit_embeds)
return vit_embeds
除上述模型初始化的相关方法外,还需要适配prepare_prefill_token和forward两种重要方法以用于前向推理。
-
prepare_prefill_token,用于得到encoder和tokenizer融合后的input_embeds、前处理、encoder、tokenizer等。
def prepare_prefill_token(self, multimodalinputs, processor): text = multimodalinputs.text image = multimodalinputs.image video = multimodalinputs.video current_query = "" if image is not None: use_dynamic_prepro = False if self.ps_version == "v1" else True pixel_values = load_and_preprocess_image(image, normalizer=self.normalizer, \ use_dynamic_prepro=use_dynamic_prepro).to(self.dtype).to(self.device) vit_embeds = self.extract_feature(pixel_values).to(self.dtype).to(self.device) image_tokens_num = self.num_image_token * vit_embeds.shape[0] current_query = (f'<img>{"<IMG_CONTEXT>" * image_tokens_num}</img>\n') elif video is not None: pixel_values, num_patches_list = load_video(video) pixel_values = pixel_values.to(self.dtype).to(self.device) vit_embeds = self.extract_feature(pixel_values).to(self.dtype).to(self.device) for i, num_patch in enumerate(num_patches_list): current_query += (f'Frame{i+1}: ' f'<img>{"<IMG_CONTEXT>" * num_patch * self.num_image_token}</img>\n') system_prompt = INTERNVL_SYSTEM_PROMPTS[self.ps_version][self.template] texts = ('<|im_start|>system\n' f'{system_prompt}<|im_end|><|im_start|>user\n') texts += current_query texts += (f'{text}<|im_end|><|im_start|>assistant\n') input_ids = processor.encode(texts) input_ids = torch.tensor(input_ids, requires_grad=False).to(self.device) input_embeds = self.llm_embedding_layer(input_ids) sequence_length, embedding_size = input_embeds.shape input_ids = input_ids.reshape(sequence_length) vit_embeds = vit_embeds.reshape(-1, embedding_size) selected = (input_ids == self.img_context_token_id) try: input_embeds[selected] = input_embeds[selected] * torch.zeros(1, dtype=self.dtype, device=self.device) + vit_embeds.reshape(-1, embedding_size) except Exception as e: error_msg = f'{e} \ninput_embeds[selected].shape is {input_embeds[selected].shape}, '\ f'vit_embeds.shape is {vit_embeds.shape}\n'\ f'Please check whether shape of input_embeds[selected] matches the shape of vit_embeds.\n'\ f'If not, please check whether self.img_context_token_id '\ f'and the token-id of "<IMG_CONTEXT>" in processor are the same.' logger.error(error_msg, ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE) raise ValueError(error_msg) from e input_embeds = input_embeds.reshape(-1, embedding_size) return input_embeds -
forward,由于底座大语言模型已适配,直接self.language_model.forward即可。
def forward( self, input_ids: torch.Tensor, position_ids: torch.Tensor, is_prefill: bool, kv_cache: List[Tuple[torch.Tensor, torch.Tensor]], block_tables: torch.Tensor, slots: torch.Tensor, input_lengths: torch.Tensor, max_seq_len: int, lm_head_indices: Optional[torch.Tensor] = None, **kwargs): if is_prefill and input_ids.dim() == 1: input_ids = self.prepare_prefill_token_service(input_ids) return self.language_model.forward(input_ids, position_ids, is_prefill, kv_cache, block_tables, slots, input_lengths, max_seq_len, lm_head_indices)
接入服务化¶
当前主流的一些三方推理后端包括Triton、TGI、VLLM和OpenAI,每个推理后端(包括MindIE)都有各自的URL请求格式。其中OpenAI的接口是独立于其他格式,因此本章节将分别介绍非OpenAI接口和OpenAI接口的服务化对接流程。
适配涉及到模型的“Router”中的tokenize()接口以及“InputBuilder”中的make_context()接口,整个接入流程将以Qwen-VL为例。
非OpenAI接口适配¶
-
服务化传递过来的输入一定是List[Dict]类型的,其中字典包含的Keys目前有:image、video、audio、text四种。示例如下:
-
tokenize() 函数实现
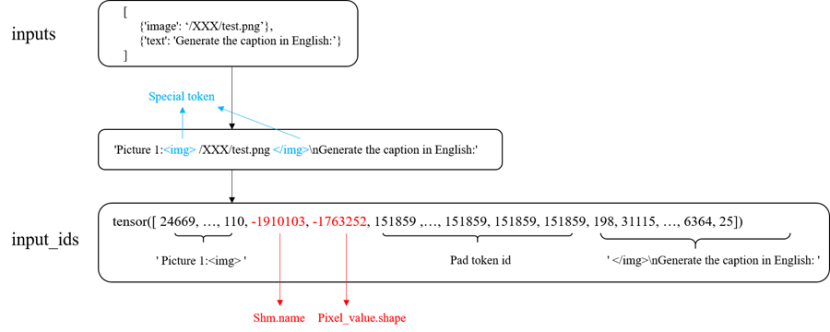
如上图所示,为输入的Prompt信息和多媒体信息在tokenizer()函数中转换为Input Id的过程。
tokenizer()函数的实现分为以下步骤:
-
将输入转换为Str类型的query,并且用特殊的token作为分割,方便后续找到要填充的位置以及嵌入共享内存的name和数据的shape。
-
对转换后的query进行encode,得到token_ids。
-
遍历输入,加载并处理多媒体数据,计算input_ids的大小,进行padding。
-
将处理好的pixel_value数据存入共享内存,需要注意:
- 需要将数据转换为numpy.ndarray才能存入共享内存。
- dtype不做限制但是在后续读取数据时需要保持一致。
-
将共享内存的name和存入数据的shape进行编码,涉及到的编码函数已在如下公共代码中定义:
“/usr/local/Ascend/atb-models/atb_llm/utils/shm_utils.py”
-
将编码好的name和shape嵌入input_ids中,返回一维的torch.Tensor(device=cpu)类型的input_ids。
代码示例如下:
def tokenize(self, inputs, **kwargs): # 1.转换 inputs 为 Str 的 query query = self.tokenizer.from_list_format(inputs) # 2. encode, qwen-vl 的这个函数是自己 padding 到固定长度,若模型是动态分辨率,请计算后再Padding input_ids = self.tokenizer([query], return_tensors="pt")["input_ids"].flatten() shm_name_save_path = kwargs.get('shm_name_save_path', None) shm_name_list = [] shape_value_list = [] image_type = "image" for single_input in inputs: if image_type not in single_input.keys(): continue # 3. 加载图片并预处理 image_pixel = _image_preprocess(single_input[image_type]) image_pixel = image_pixel[None, :] # ***************** Important Attention ********************************** # if shm_name_save_path is None: shm_name_save_dir = os.path.dirname(os.path.dirname(single_input[image_type])) shm_name_save_path = os.path.join(shm_name_save_dir, "shm_name.txt") # ******************** Important Attention ******************************** # # 4. 存入共享内存 shm = create_shm(image_pixel.nbytes, shm_name_save_path) shared_array = np.ndarray(image_pixel.shape, dtype=np.float32, buffer=shm.buf) shared_array[:] = image_pixel # 5. 将共享内存的 name 编码为 int64, 将存入的Pixel value的shape编码为 int64 shm_name = encode_shm_name_to_int64(shm.name) shape_value = encode_shape_to_int64(image_pixel.shape) shm_name_list.append(shm_name) shape_value_list.append(shape_value) # 6. 将编码后的 name 嵌入 input_ids, 将编码后的 shape 嵌入 input_ids image_start_id = self.config.visual["image_start_id"] bos_pos = torch.where(torch.eq(input_ids, image_start_id))[0] image_num = bos_pos.shape[0] for i in range(image_num): input_ids[bos_pos[i] + 1] = shm_name_list[i] input_ids[bos_pos[i] + 2] = shape_value_list[i] return input_ids说明
代码中标注了一段Important Attention代码,代码片段中的shm_name_save_path变量是用来存放共享内存地址的文件路径,以便在服务侧从该文件中读取共享内存地址释放共享内存。服务侧释放资源强依赖于传入的多媒体数据路径,因此服务化时该参数必须为“None”。 - 如果是服务化调用这个接口,则该参数默认为None,代码直接通过服务侧传递过来的多媒体路径寻找。 - 如果是纯模型侧调用接口,请指定该参数,并且在run_pa.py模型推理之后释放共享内存。详情可以参考Qwen-VL的run_pa.py。 示例如下:>
-
-
forward() 多媒体数据处理
模型的flashcacusal类的forward()中,实际就是tokenize()的逆变换。
以Qwen-VL为例,forward()主要有以下操作步骤:
- 通过特殊的token找到多媒体数据的插入位置。
- 解码共享内存的name和数据的shape,从共享内存取出处理好的数据。需要注意get_data_from_shm()的第三个入参dtype是指存入共享内存时的类型,需要与存入时保持一致才能正确取出,这个函数返回tensor。
- 将上一步取出的shared_array送入处理多媒体数据的网络得到hidden features。
- 用hidden features替换掉input_ids中的pad tokens。
代码示例如下:
def forward( self, input_ids: torch.Tensor, ... ) -> torch.Tensor: if not self.ascend_weight: self.init_ascend_weight() self.init_kvcache(kv_cache) hidden_states = self.transformer.wte(input_ids) if is_prefill: if torch.any(torch.eq(input_ids, self.image_start_id)): # 1. 通过特殊的`token`找到多媒体数据的插入位置 bos_pos = torch.where(torch.eq(input_ids, self.image_start_id))[0] eos_pos = torch.where(torch.eq(input_ids, self.image_start_id + 1))[0] image_num = bos_pos.shape[0] images = [] pixel_array = [] for i in range(image_num): # 2. 解码共享内存的`name`和数据的`shape`,从共享内存取出处理好的数据 shm_value = input_ids[bos_pos[i] + 1] shape_value = input_ids[bos_pos[i] + 2] shared_array = get_data_from_shm(shm_value, shape_value, np.float32, self.device) pixel_array.append(shared_array) # 3. 送入ViT得到`hidden features` if len(pixel_array) != 0: pixel_array = torch.cat(pixel_array, dim=0) images = self.visual(pixel_array) else: images = self.visual.encode(images) # 4. 用`hidden features`替换掉`pad tokens` for i in range(image_num): hidden_states[bos_pos[i] + 1 : eos_pos[i]] = images[i] acl_inputs, acl_param = self.prepare_inputs_for_ascend( ... ) logits = self.execute_ascend_operator(acl_inputs, acl_param, is_prefill) return logits
OpenAI接口适配¶
服务侧接收到请求之后会调用tokenize(),当请求是OpenAI的格式时,将调用模型侧的InputBuilder类的make_context()接口。
-
InputBuilder类
适配新的多模态模型对接服务化时,需要创建一个新的子类_“XXXInputBuilder”_继承基类“InputBuilder”,并重写make_context()这个类方法。
以Qwen-VL为例 ,下面是QwenVlInputBuilder的类图。完成该类重写后,需要在模型的Router的get_input_builder()中完成实例化。对应文件路径位于“/usr/local/Ascend/atb-models/atb_llm/models/qwen/router_qwen.py”

-
make_context() 函数输入
OpenAI格式的请求,在输入上变为List[Dict[str, Dict]]格式,可以支持多轮对话的输入。每一轮对话是Dict,其中多出两个字段“role”和“content”,“role”表示这一轮对话的角色,“content”表示这一轮对话的内容,其格式与1一致。
代码示例如下:
-
make_context() 函数实现
这个函数实现的目的与tokenize()是一致的,都是将输入转换为input_ids。不过这个函数通常是以模型支持的chat template来安排整个内容。
此函数的实现步骤与tokenize()函数的一致,主要是多了下面的步骤b.。下面的实现步骤顺序不强制,可以按照实际实现调整。
a. 将输入转换为str类型的query,并且用特殊的token作为分割。 b. 按照template拼接内容。 c. 对转换后的query进行encode,得到token_ids。 d. 遍历输入,加载并处理多媒体数据,计算input_ids的大小,进行padding。 e. 将处理好的pixel_value数据存入共享内存。 f. 将共享内存的name和存入数据的shape进行编码。 g. 将编码好的name和shape嵌入input_ids中,返回一维的torch.Tensor(device=cpu)类型的input_ids。
代码示例如下:
def make_context( self, rank: int, conversation: List[Dict[str, List[Dict]]], system: str = "You are a helpful assistant.", **kwargs): if self.generation_config["chat_format"] != 'chatml': raise ValueError(_ERROR_BAD_CHAT_FORMAT) if not isinstance(conversation[0]["content"], list): raise ValueError("The conversation \"content\" should be a List[Dict].") shm_name_save_path = kwargs.get('shm_name_save_path', None) self.rank = rank max_window_size = kwargs.get('max_window_size', None) if max_window_size is None: max_window_size = self.generation_config["max_window_size"] context_tokens = self._apply_chat_template( conversation, system=system, max_window_size=max_window_size, shm_name_save_path=shm_name_save_path, ) return context_tokens def _apply_chat_template( self, conversation: List[Dict[str, List[Dict]]], system: str = "", max_window_size: int = 6144, shm_name_save_path: str = None, **kwargs): # 1. 获取特殊 Token im_start_tokens = [self.tokenizer.im_start_id] im_end_tokens = [self.tokenizer.im_end_id] nl_tokens = self.tokenizer.encode("\n") system_tokens_part = self._tokenize_str("system", system, nl_tokens) system_tokens = im_start_tokens + system_tokens_part + im_end_tokens shm_name_list = [] shape_value_list = [] content_key = "content" image_key = "image" for message in conversation: for single_input in message[content_key]: if image_key not in single_input.keys(): continue # 4. 遍历输入,加载并处理多媒体数据,计算`input_ids`的大小,进行`padding` image_pixel = _image_preprocess(single_input[image_key]) image_pixel = image_pixel[None, :] if shm_name_save_path is None: shm_name_save_dir = os.path.dirname(os.path.dirname(single_input[image_key])) shm_name_save_path = os.path.join(shm_name_save_dir, "shm_name.txt") shm = shm_utils.create_shm(image_pixel.nbytes, shm_name_save_path) shared_array = np.ndarray(image_pixel.shape, dtype=np.float32, buffer=shm.buf) shared_array[:] = image_pixel # 5. 将处理好的`pixel_value`数据存入共享内存 # 6. 将共享内存`name`和存入数据的`shape`编码 shm_name = shm_utils.encode_shm_name_to_int64(shm.name) shape_value = shm_utils.encode_shape_to_int64(image_pixel.shape) shm_name_list.append(shm_name) shape_value_list.append(shape_value) # 1. 将输入转换为`Str`类型的`query`,并且用特殊的`token`作为分割 context_tokens = system_tokens query = self.tokenizer.from_list_format(conversation.pop()[content_key]) for message in conversation[::-1]: turn_query = self.tokenizer.from_list_format(message[content_key]) if message["role"] == self.user_role_name: query_tokens = nl_tokens + im_start_tokens + \ self._tokenize_str(self.user_role_name, turn_query, nl_tokens) + im_end_tokens + nl_tokens elif message["role"] == self.system_role_name: query_tokens = im_start_tokens + \ self._tokenize_str(self.system_role_name, turn_query, nl_tokens) + im_end_tokens else: raise ValueError(f"message role not supported yet: {message['role']}") current_context_size = ( len(system_tokens) + len(query_tokens) + len(context_tokens) ) if current_context_size < max_window_size: context_tokens = query_tokens + context_tokens else: break # 2. 按照`template`拼接内容 context_tokens += ( nl_tokens + im_start_tokens + self._tokenize_str(self.user_role_name, query, nl_tokens) # 对转换后的`query`进行`encode`,得到`token_ids` + im_end_tokens + nl_tokens + im_start_tokens + self.tokenizer.encode(self.system_role_name) + nl_tokens ) # 7. 将编码好的`name`和`shape`嵌入`input_ids`中,返回一维的`torch.Tensor`(cpu)类型的`input_ids` context_tokens_tensor = torch.tensor(context_tokens) bos_pos = torch.where(torch.eq(context_tokens_tensor, self.image_start_id))[0] image_num = bos_pos.shape[0] for i in range(image_num): context_tokens[bos_pos[i] + 1] = shm_name_list[i] context_tokens[bos_pos[i] + 2] = shape_value_list[i] return context_tokens -
Router 中重写 get_input_builder()
服务侧会通过模型的Router的get_input_builder()接口获取每个模型侧InputBuilder,因此请务必重写该函数。