Attention量化¶
简介¶
此量化方式将q,k,v量化为8bit,通过减少KV Cache的显存占用,优化decode阶段attention算子的速度,提升吞吐。
说明
- 仅Atlas 800I A2 推理服务器支持Attention量化。
- 仅支持W8A8配合使用。
- 仅支持LLaMA3.1-70B。
- 仅支持和长序列特性、Function Call配合使用。
Attention量化搭配W8A8量化后权重目录结构:
├─ config.json
├─ quant_model_weight_w8a8.safetensors
├─ quant_model_description.json
├─ tokenizer_config.json
├─ tokenizer.json
└─ tokenizer.model
- 量化输出包含:权重文件quant_model_weight_w8a8.safetensors和权重描述文件quant_model_description.json。
- 目录中的其余文件为推理时所需的配置文件,不同模型略有差异。
以下展示了量化后权重描述文件quant_model_description.json中的部分内容:
{
"model_quant_type": "W8A8",
"fa_quant_type": "FAQuant",
"model.embed_tokens.weight": "FLOAT",
"model.layers.0.self_attn.q_proj.weight": "W8A8",
"model.layers.0.self_attn.q_proj.input_scale": "W8A8",
"model.layers.0.self_attn.q_proj.input_offset": "W8A8",
"model.layers.0.self_attn.q_proj.quant_bias": "W8A8",
"model.layers.0.self_attn.q_proj.deq_scale": "W8A8",
"model.layers.0.self_attn.k_proj.weight": "W8A8",
"model.layers.0.self_attn.k_proj.input_scale": "W8A8",
"model.layers.0.self_attn.k_proj.input_offset": "W8A8",
"model.layers.0.self_attn.k_proj.quant_bias": "W8A8",
"model.layers.0.self_attn.k_proj.deq_scale": "W8A8",
"model.layers.0.self_attn.v_proj.weight": "W8A8",
"model.layers.0.self_attn.v_proj.input_scale": "W8A8",
"model.layers.0.self_attn.v_proj.input_offset": "W8A8",
"model.layers.0.self_attn.v_proj.quant_bias": "W8A8",
"model.layers.0.self_attn.v_proj.deq_scale": "W8A8",
"model.layers.0.self_attn.o_proj.weight": "W8A8",
"model.layers.0.self_attn.o_proj.input_scale": "W8A8",
"model.layers.0.self_attn.o_proj.input_offset": "W8A8",
"model.layers.0.self_attn.o_proj.quant_bias": "W8A8",
"model.layers.0.self_attn.o_proj.deq_scale": "W8A8",
}
和W8A8量化权重相比,新增fa_quant_type描述字段,新增self_attn字段及下面包含的内容,input_scale用于将q,k,v特征量化为int8类型,deq_scale用于将q,k,v输出反量化成浮点类型。
图 1 量化权重推理时流程
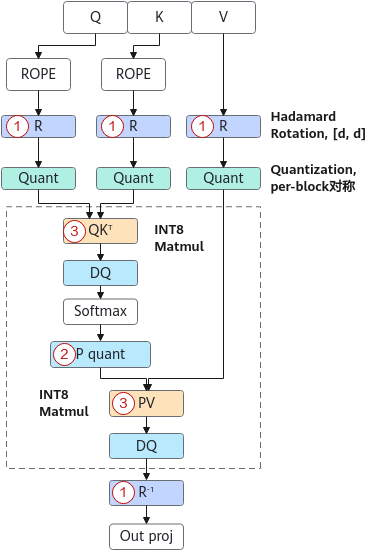
表 1 float16权重量化后dtype及shape信息(假设原始权重的shape为[n, k])
| Tensor信息 | dtype | shape |
|---|---|---|
| q_scale | float16 | [q_head_num, head_dim] |
| q_offset | float16 | [q_head_num, head_dim] |
| k_scale | float16 | [kv_head_num, head_dim] |
| k_offset | float16 | [kv_head_num, head_dim] |
| v_scale | float16 | [kv_head_num, head_dim] |
| v_offset | float16 | [kv_head_num, head_dim] |
表 2 bfloat16权重量化后dtype及shape信息(假设原始权重的shape为[n, k])
| Tensor信息 | dtype | shape |
|---|---|---|
| q_scale | bfloat16 | [q_head_num, head_dim] |
| q_offset | bfloat16 | [q_head_num, head_dim] |
| k_scale | bfloat16 | [kv_head_num, head_dim] |
| k_offset | bfloat16 | [kv_head_num, head_dim] |
| v_scale | bfloat16 | [kv_head_num, head_dim] |
| v_offset | bfloat16 | [kv_head_num, head_dim] |